Implications of data aggregation method on crop model outputs – The case of irrigated potato systems in Tasmania, Australia
Abstract
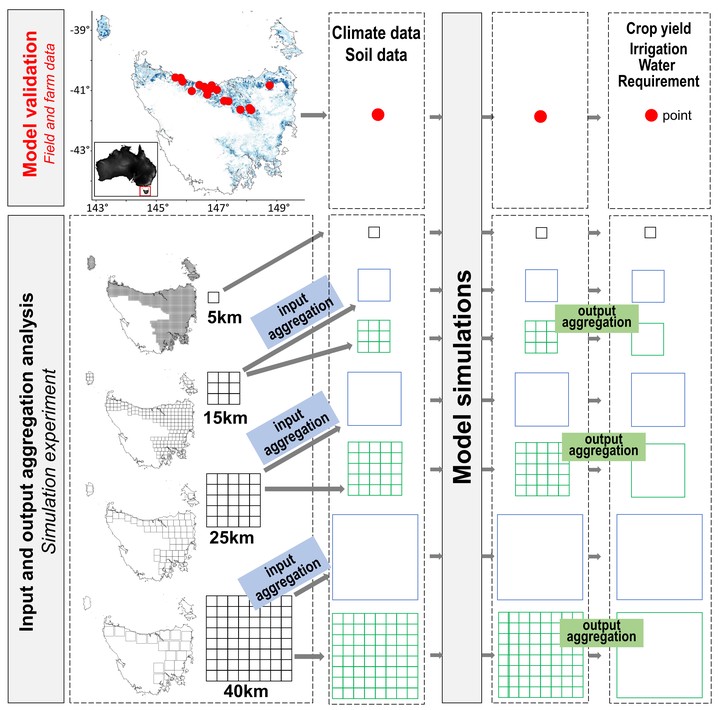
Crop models were originally developed for application at the field scale but are increasingly used to assess the impact of climate and/or agronomic practices on crop growth and yield and water dynamics at larger scales. This raises the question of how data aggregation approaches affect outputs when using crop models at large spatial scales. This study investigates how input and output data aggregation affected simulated rainfed and irrigated potato yield and irrigation water requirement (IWR) across potato production areas in Tasmania, Australia. First, the yield and IWR with aggregated model inputs at 15, 25 and 40 km resolutions (input aggregation) was simulated. Second, simulated model outputs generated with high-resolution input data were aggregated to 15, 25 and 40 km resolutions (output aggregation) and compared to the corresponding yield and IWR with simulations based on input data aggregation. Finally, the differences (D) (DY and DIWR for yield and IWR, respectively) between grids using input and output aggregation were evaluated. The results indicate that the effect of input and output data aggregation on yield depends on water-driven factors including plant available water capacity (PAWC), rainfall and irrigation. Maximum D values were found for rainfed yield (4.4 t ha-1) and IWR (137 mm). DY variations were correlated with the differences of PAWC caused by data aggregation in 82 % of potato production areas. Differences between aggregation methods were reduced when growing season rainfall increased. We conclude that PAWC and the source of water (rainfall or rainfall + irrigation) explained the larger errors associated with the input and output data aggregation on simulated potato yield and IWR. Future studies should consider the data aggregation method in their assessment to minimize errors and therefore produce higher quality advice or farming decisions.