Assessing errors during simulation configuration in crop models – A global case study using APSIM-Potato
Abstract
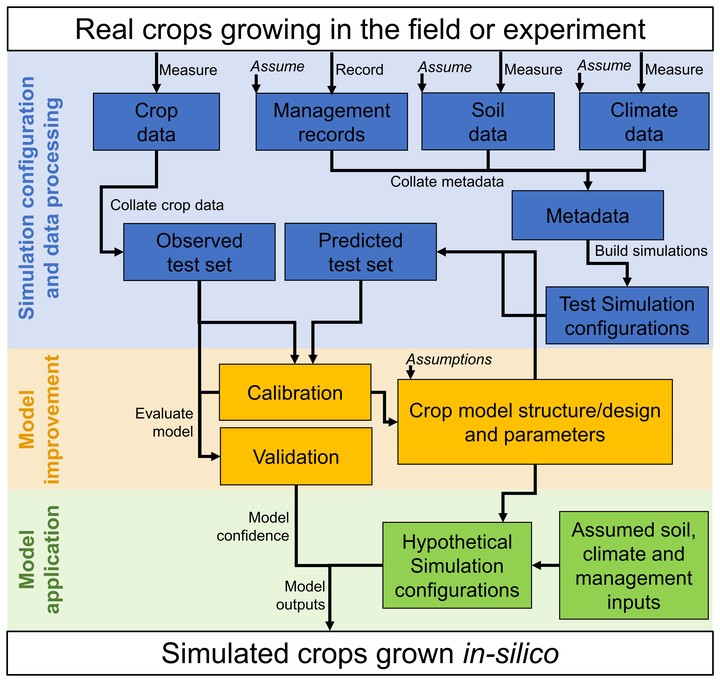
Crop models are usually developed using a test set of data and simulations representing a range of environment, soil, management and genotype combinations. Previous studies demonstrated that errors in the configuration of test simulations and aggregation of observed data sets are common and can cause major problems for model development. However, the extent and effect of such errors using Agricultural Production system SIMulator Next Generation (APSIM) crop models are not usually considered as a source of model uncertainty. This is a methodological paper describing several approaches for testing the APSIM simulation configuration to detect anomalies in the input and observed data. In this study, we assess the simulation configuration process through (i) quality control analysis based on a standardised climate dataset (ii) outlier identification and (iii) a palette of visualization tools. A crop model – APSIM-Potato is described to demonstrate the main sources of error during the simulation configuration and data collation processes. Input data from 426 experiments conducted from 1970 to 2019 in 19 countries were collected and configured to run a model simulation. Plots were made comparing simulation configuration data and observed data across the entire test set so these values could be checked relative to others in the test set and with independent datasets. Errors were found in all steps of the simulation configuration process (climate, soil, crop management and observed data). We identified a surprising number of errors and inappropriate assumptions that had been made which could influence model predictions. The approach presented here moved the bulk of the effort from fitting model processes to setting up broad simulation configuration testing and detailed interrogation to identify current gaps for further model development.